Research
Overview
Main
Areas of Research:
Our research
activities are
centered around the development
of statistical methodology and its
application in
contemporary and challenging data
analyses. One of our main goals is to
provide
statistical models that are easy to
interpret and can thus
convey the results found in the data in a
clear and concise way.
The focus of our research is on:
- Analysis of
categorical and discrete data
structures
- Regularization and structured
regression
Project
Overview:
Research
Projects:
| DFG
Project
"Regularization for Discrete
Data
Structures" |
|
Principal investigator: Gerhard Tutz
Staff: Margret
Oelker, Wolfgang
Pößnecker
|
Statistical modelling
of
discrete
structures
requires
vast
amounts
of
parameters.
Even
treating only a handful of
discrete features yields
high-dimensional models if
these features have many
levels. A possible
way of dealing with these
high-dimensional
situations are modern
regularization
techniques which allow for
estimable and
interpretable models.
Existing
regularization approaches,
however, focus almost
exclusively on
continuous variables.
Therefore, the goal of
this project is to develop
regularization
techniques
that are tailored
specifically to models
with a discrete structure.
A
major goal at this is that
the resulting models are
easy to interpret,
which is crucial for real
world applications.
Interpretability is
achieved by a
regularization that yields
a parsimonious
parameterization and, at
the same time, accounts
for the special
structure of the
respective model.
One of the objects of
study are classical
regression models with
categorical predictors and
models for discrete
dependent variables.
Another
major area of research are
models with categorical
effect-modifying
variables and finite
mixture models, which
account for
heterogeneity in the data
by the interaction of the
other covariates
with an observed or latent
discrete feature. The
focus in these models
is similar and lies in a
variable selection that is
suitable for
discrete
features, the clustering
of similar categories and
the distinction
between category-specifc
and global
parameterizations.
|
|
CEST
"Center for
Empirical Studies
(CEST): Data
Analysis,
Modelling &
Knowledge
Discovery in
Social Sciences,
Economics and
Humanities" |
 |
|
Coordination: Gerhard
Tutz |
|
The Center
of
Empirical Studies
is a
research
initiative linking
empirical and
methodological
research groups
from several
different
faculties.
Methodological
challenges include
modeling
unobservable
heterogeneity or
measuring latent
traits, that recur
in similar form
in, for example,
economic,
sociological and
psychological
tasks. The
aim of the Center
for Empirical
Studies is thus to
enhance the
explanatory power
of empirical
studies by means
of new
methodological
developments. The
initiative is
organized in three
interacting areas:
Statistical
Learning, Data
Mining &
Knowledge
Discovery,
Measurement &
Evaluation and
Dynamic Modeling.
|
|
| CEST
Project"Dynamical
Modelling:
Forecasting
Models using
Business
Surveys" |
| Kai
Carstensen,
Gerhard
Tutz |
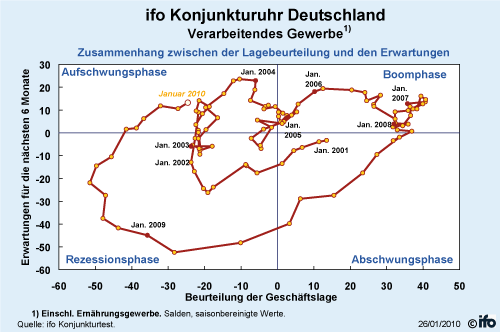
The
identification
of the current
state in
the business
cycle and the
forecast of the
next quarters do
not only receive
a lot of
attention in
the public, they
are also of
prime importance
for the plans of
firms
and the
government. The
most important
leading
indicator for
the German
economy is the
ifo Business
Climate Index
that is based on
a monthly
business survey
with more than
7,000
respondents. Due
to the large
number of firms,
the results can
be analysed at a
disaggregate
level
for the
different
sectors, firms
and response
categories.
Thus, it is
possible to use
a panel of
sector-specific
survey indices
in order to
forecast the
sectoral gross
value added or
to examine
whether they are
leading
important
aggregate
variables like
total gross
value added or
gross domestic
product (GDP).
A
number of
questions are
of interest:
- Are there
sectors or
firms that
have
stable leading
properties to
the target
series?
- Are there
interactions
between
sectors or
firms that
attenuate or
intensify the
original
signal?
- What is
the delay with
which
firms react
to
macroeconomic
impulses?
Which
explanations
can be found?
Due to the large
number of
possible
lead-lag
relationships
and the
additional
difficulty of
time-varying
structures it
seems necessary
to
pre-select
factors that are
relevant for the
question of
interest.
Modern selection
methods such as
parametric and
nonparametric
boosting
or random
forests will be
adapted to the
problem at hand.
|
|
| CEST
Project"Dynamical
Modelling:
Modelling of
Sojourn Time" |
| Kai
Carstensen,
Gerhard
Tutz |
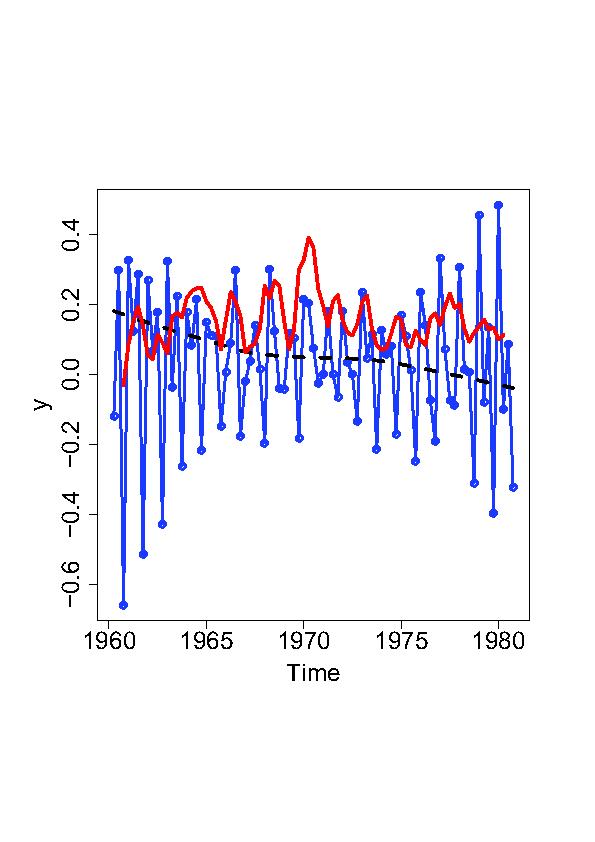
The
modelling of
sojourn time is
crucial for
grasping the
dynamics of
response
behavior in
panel surveys.
Particularly the
Ifo Business
Survey, which is
conducted
monthly among
7,000
participating
firms, is an
excellent basis
for the analysis
of
nonresponse
behaviour in
business surveys
because it can
build on an
enormous data
set. The main
research tasks
that can be
answered by
means of
business surveys
concern
nonresponse
behavior and
expectations
at the firm
level.
Nonresponse
considerably
influences the
stability of
the data and can
create a bias in
the results.
While severals
analyses
of the issue are
available for
individual and
houshold
surveys, there
is little
research on
processes and
sources of
compliance in
business
surveys. The
main factors
responsible for
"panel fatigue",
i.e. a
decreasing
compliance over
time, can be
used to improve
the quality and
uncover present
selectivity. At
the firm level,
the analysis of
expectations is
of special
interest,
particularly
because current
macroeconomic
models emphasize
the importance
of expectations
to
explain business
cycle dynamics.
However, it
often turns out
empirically that
the standard
assumption of
rational
expectations
does
not hold. Since
the surveys of
the Ifo
Institute also
contain
expectational
categories, they
allow a deeper
analysis of the
process
of expectation
formation. An
interesting
question is in
how far current
expectations
correlate and
interact with
previous
expectations and
other response
categories,
especially with
future
realizations.
Methodological
problems for the
Ifo data arise
from the fact
that the
responses of the
enterprises are
given in
categorical form
(e.g.,
“better”,
“unchanged”,
“worse”). In the
corresponding
competing risk
approaches, the
question needs
to be evaluated
whether the
monthly
survey allows
for discrete or
continuous
modelling. In
general, the
empirical
analysis of
sojourn time
data often shows
that the effect
of
influencing
variables varies
over time.
Ignoring these
effects often
results in
artificial
effect sizes and
reduced
prediction
accuracy. In
order to model
these variations
adequately, it
is necessary to
incorporate
time-varying
effects in
nonparametric
form. This leads
to
severe selection
problems: which
variables should
be modelled
parametrically
to be
time-constant
and which
nonparametrically
to be
time-varying?
The selection
problems are to
be solved by
means of
modern selection
techniques like
the Lasso and
Boosting.
Especially the
generalization
to multi-state
models and the
modelling of
heterogeneity
are of
substantial
interest for the
intended
analysis of the
Ifo
business survey
as well as other
econometric and
sociological
surveys.
|
|
| CEST
Project"Measurement
and Evaluation:
New Methods for
Item Response
Theory" |
| Strobl,
Lindmeier,
Reiss,
Gerhard
Tutz |
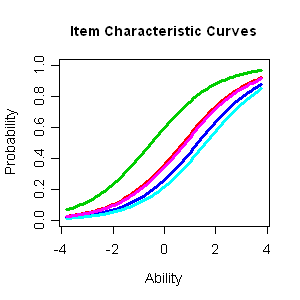
Item
Response Theory
(IRT) is one of
last
century's most
important
achievements of
psychological
diagnosis and
empirical
educational
research: It
allows for an
objective
measurement
of latent person
characteristics
by means of
separating item
and person
parameters.
Moreover, as
opposed to the
classical
psychological
measurement
theory, IRT
provides the
opportunity to
statistically
test
the model
assumptions. The
Rasch model,
which has been
used in the
PISA-study, is
the most
well-known IRT
model.
In an
intervention
study on the
effectiveness of
competence-supporting
learning
environments the
Rasch model was
emplyed to
measure
mathematical
comptetency for
using diagrams
and models in
statistical
contexts. In
this study, both
the objective
measurement of
the
students'
competencies and
the modelling of
the treatment
effects is of
major interest.
Methodological
challenges arise
from the
heterogeneity
of the sample:
The data have a
hierarchical
structure,
because students
are grouped in
classes, classes
in schools and
so forth.
Moreover it is
necessary to
check whether
the measures are
comparable for
students
from different
groups, or if
differential
item functioning
occurs.
The aim of the
project is to
develop and
apply new IRT
Methods to
account for the
sample
heterogeneity:
For the
diagnosis of
differential
item functioning
methods from
machine learning
will be used in
combination with
latent-class-approaches.
The hierarchical
data
structure will
be accounted for
by means of
mixed models.
|
|
|
| LMUinnovativ
Project "Analysis and
Modelling of Complex
Systems in Biology and
Medicine" (Biomed-S) |
 |
Coordinator: Torsten
Hothorn
Principal investigator: Gerhard
Tutz |
The general aim of
this project is
the modelling and analysis
of complex biological and
biomedical systems
with methods from
bioinformatics,
mathematics, physics and
statistics
in cooperation with
partnern in biology and
medicine. The main focus
is
on pioneering areas of
post genomics including
systems biology and
their applications in
medicine and
pharmaceutics, but also
goes beyond
to population biology. The
project consists of three
incorporated
clusters:
- Cluster A:
Quantitative biology
and
biostatistics
- Cluster B: Complex
Systems in molecular
medicine
- Cluster C:
Structures and
dynamics of
functional modules in
model organisms
|
|
Former
Research Projects:
| DFG Project: "Model Based
Feature Extraction and
Regularisation in
High-dimensional Structures" |
 |
Principal investigator: Gerhard Tutz
Staff: Jan
Gertheiss |
Feature extraction
aims at detecting
influential
structures or patterns in
data. The focus of the
project is on model
based feature selection
methods where the
predictor space is linked
to
the target criterion by
parametric or
semiparametric models and
features are extracted
with reference to the
modelling approaches. The
supervised learning
techniques that are
considered explicitly use
the
target criterion in the
feature selection process
in contrast to widely
used two-step approaches
where in the first step
unsupervised learning
is applied to extract
features and only in the
second step the features
are linked to the target.
The type of model used
depends on the data
structure and the
objective
of modelling. One area of
investigation is
functional data where
predictors are given as
signals. Feature
extraction then makes use
of
the information in the
underlying metric space.
These spatial
methods tend to show
better performance than
equivariant methods where
no ordering of predictors
is used. For predictors
without ordering, the
focus is on the selection
of variables when groups
of highly correlated
variables and different
types of variables are
present.
|
|
|